A finite-time evasion strategy in pursuit-evasion games using multi-agent reinforcement learning
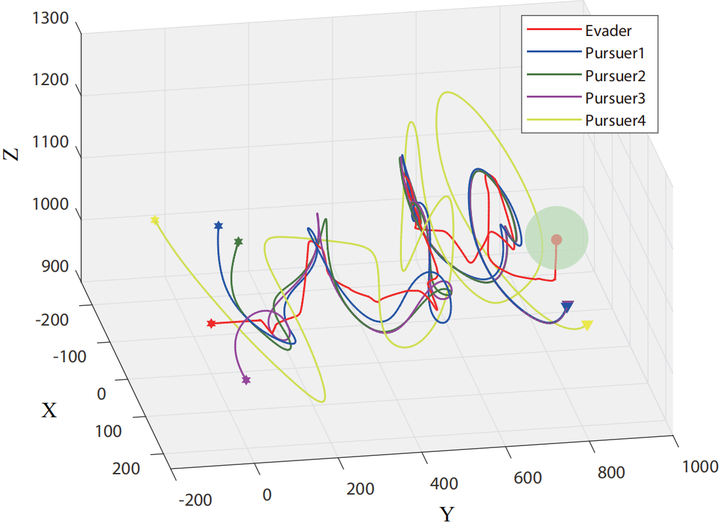 Illustration of the training end cases in pursuit-evasion games for aerial robots.
Illustration of the training end cases in pursuit-evasion games for aerial robots.Abstract
In this paper, a whole novel method, called manoeuvrability enhanced reinforcement learning via gaussian process (MERL-GP), is proposed to deal with problems including escape strategy, local optima, and uncertainty for multi-robot high-dimensional data. MERL-GP contains manoeuvrability action, composite reward mechanism, and gaussian process. Specifically, manoeuvrability action provides more escape strategies. Composite reward mechanism overcomes the sparse reward and local optima problems. Gaussian process approximation solves the Q-function and allows an accurate online update of the parameters of the posterior mean and covariance. Simulation and experiment results on escape tasks for ground and aerial robots demonstrate the effectiveness and robustness of our method.